Octopus Deploy in 2020
This post is a summary of Octopus Deploy as of May 2020. Our team, our customers, what we do, and how we see the DevOps automation world.

Since I wrote on this blog six years ago, so much has happened. Where do I even start? I think it might be helpful to start with a recap of where we're at right now, so my future posts make a bit more sense.
This post is a snapshot of Octopus as of May, 2020.
Meet the team

The Octopus Deploy team today is just under 70 people. You can find a full, up to date list of everybody on our company page. We're a remote, geographically distributed team, and have been since we started.
A bit over half of us live in Brisbane, Australia, where we have a small office in the Brisbane CBD (the same office we opened in 2014). People might come into the office one or two days a week, or for training and onboarding, but for the most part, people work from home.
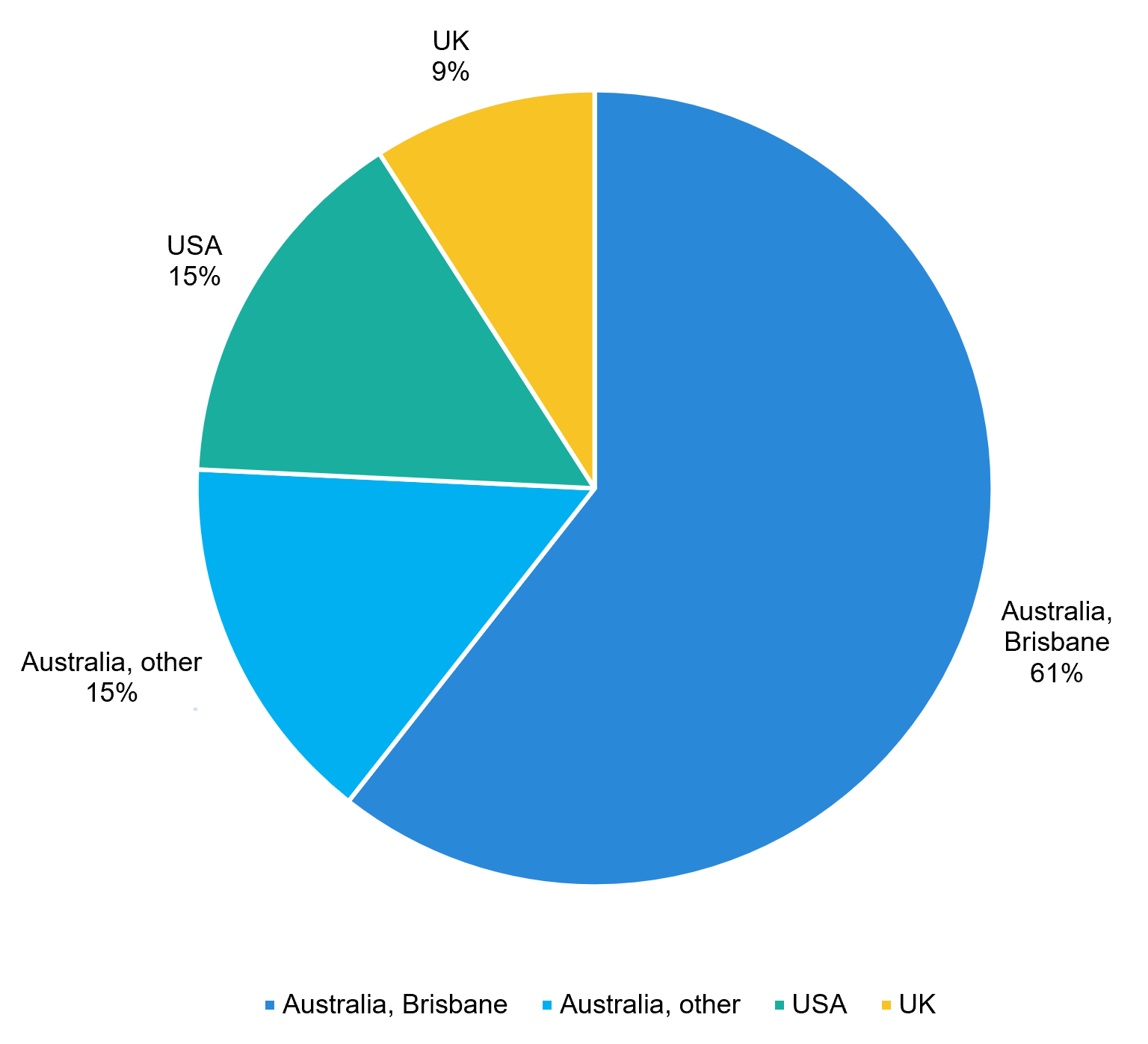
Outside of Brisbane, we have team members distributed around Australia, and the US and UK. It looks like this:
Why is our team geographically distributed?
Although most of the team is in Australia, only 9% of our customers are in Australia or nearby. Australia suffers from the "tyranny of timezone overlap" - we have very little overlap with the US and Europe, just one or two hours usually at most. Occasionally, I talk to founders in Europe who complain that they "only" have 3-4 hours overlap with the US. What I would give!
50% of our customers are in the US or Canada, and 40% are in the UK and Europe. So our teams tend to be distributed according to that.
Working from home in the same region is hard, but collaborating across timezones with little overlap is an order of magnitude harder. So where possible, we've tried to keep teams either centralized in a timezone/region or limit the team to two major timezone regions. Here's how it's turned out in practice:
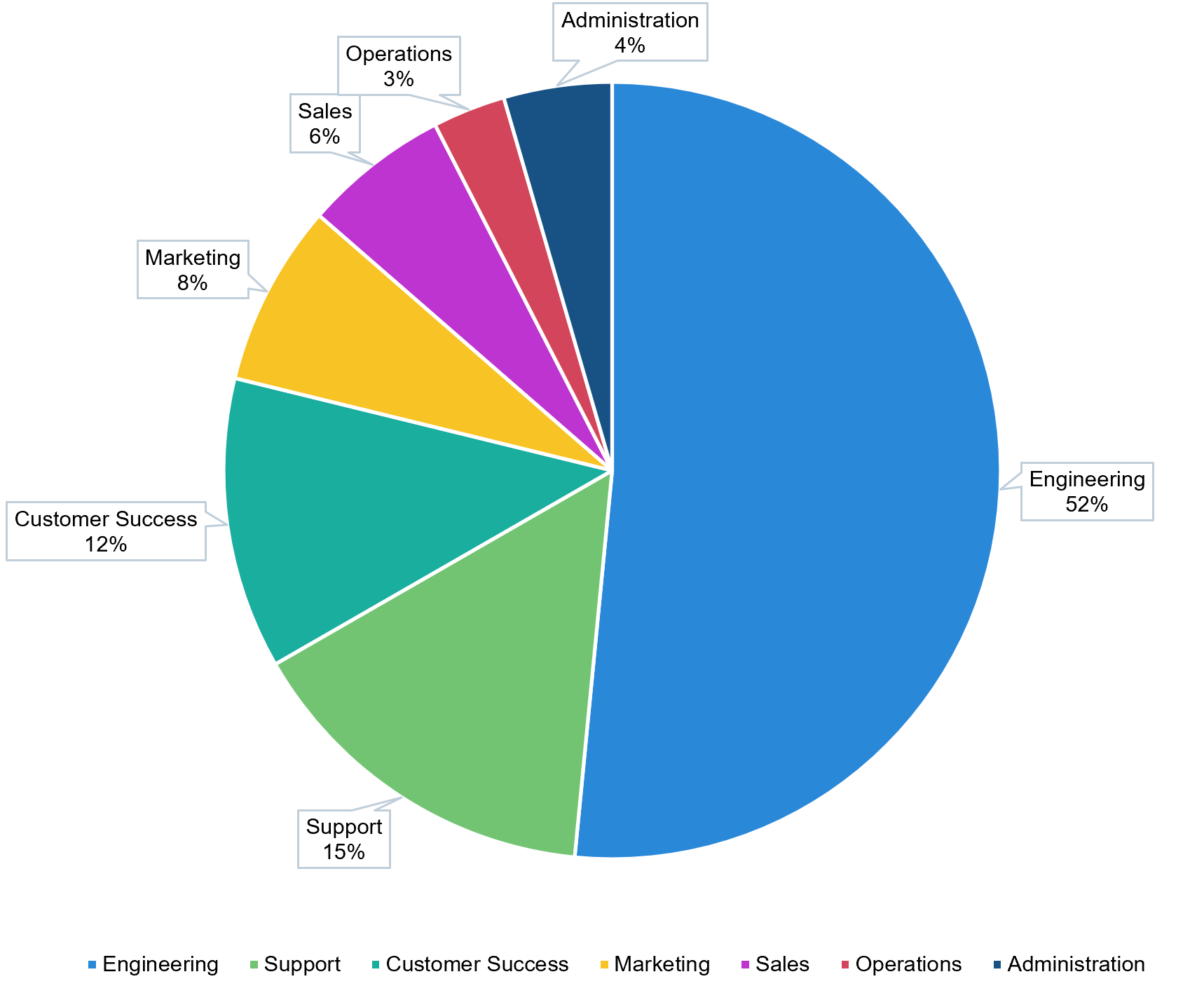
- Our Customer Success team is split 50/50 between the US and UK. This team spends their time doing webinars, attending events, and generally being experts on CI/CD and DevOps. They also spend a lot of time working with larger customers helping them succeed with Octopus.
- Our Sales team is split between Australia and the US. The US team has a few hours overlap with the UK.
- Our Support team is split evenly between the US, UK, and Australia. It's necessary for them to be close to our customers and close to engineering because they deal with some very thorny environment issues. Because of the three timezones, there's no convenient time to be on a Zoom call together, so they have the most challenging arrangement.
- Our Engineering, Product, Marketing, and Finance teams are all centralized in Australia.
(If you are wondering how employment works - we set up subsidiary companies in the US and UK, and employ everybody directly as employees, not contractors.)
Octopus is a very R&D heavy company. I've noticed that software companies tend to come in two flavors - they are either very sales/marketing heavy (Zoom) or very R&D heavy (Atlassian). We might even be too R&D heavy. Here's how our team breaks up between the departments:
(I'd like to say this was a strategic and deliberate decision, but in all honesty, it's more reflective of my strengths & weaknesses as a CEO. It's taken me a long time to figure out what sales and marketing do!)
Meet our customers
A bit over 25,000 companies use Octopus Deploy today. Many of them use Octopus for free - either our free Server or Cloud edition. About 10,000 of them are paying customers. No single customer accounts for more than 1% of our revenue.
We count customers by email domain - if you have "@ford.com" in your email address, you are Ford. Many of those customers then have multiple licenses (different teams or departments).

The tipping point for Octopus tends to be companies with 200 employees. They typically have engineering teams large enough to want to standardize on deployment tooling, and complex enough deployments to need a tool that's powerful. While plenty of smaller companies and one-person shops use Octopus too, I'd say that the "pain" Octopus solves tends to be more obvious when there is at least a modestly sized engineering team.
We price our software so that companies can use us for free before they really have to, so that when they reach that tipping point they are ready to get lots of value as they begin to pay us.
Octopus also has thousands of Enterprise customers (companies with thousands of employees). Something I'm particularly proud of is that we've done all this without a traditional enterprise sales team, which is different from all the other companies in our space. Ironically, we’re the largest Enterprise deployment software provider, dspite the fact we don’t have an Enterprise sales force.
Rather than sold to the CTO or DevOps Manager by a commissioned salesperson, Octopus gets adopted bottom-up by individual engineering teams, which standardize on it by consensus. Everyone tells me we need an enterprise sales team, but so far, we've avoided it. It's true that we've missed out on some customers because someone else came in and sold to their boss top-down, but often their engineering teams adopt us anyway, because we solve the actual problem, rather than the distorted version of that problem that our competitors have been forced to present. We can afford to be patient because our costs are low and our profitability high.
Our strategy & what we do
In this section, I'm going to make a few comments on our competitors. It's hard to explain our strategy and why we are different without sharing my take on the rest of the market. As you would expect, I'm biased, so please read all this as opinion, not fact.
Octopus got rolling in 2012, and back then, the choice for most teams was to script deployments manually or to use Octopus - there weren't many other options. If you worked at a very large company, you might have been forced to use one of the Big Enterprise release management tools that was sold to your CTO (by IBM or CA); but for the most part, people rolled their own solutions or deployed manually.
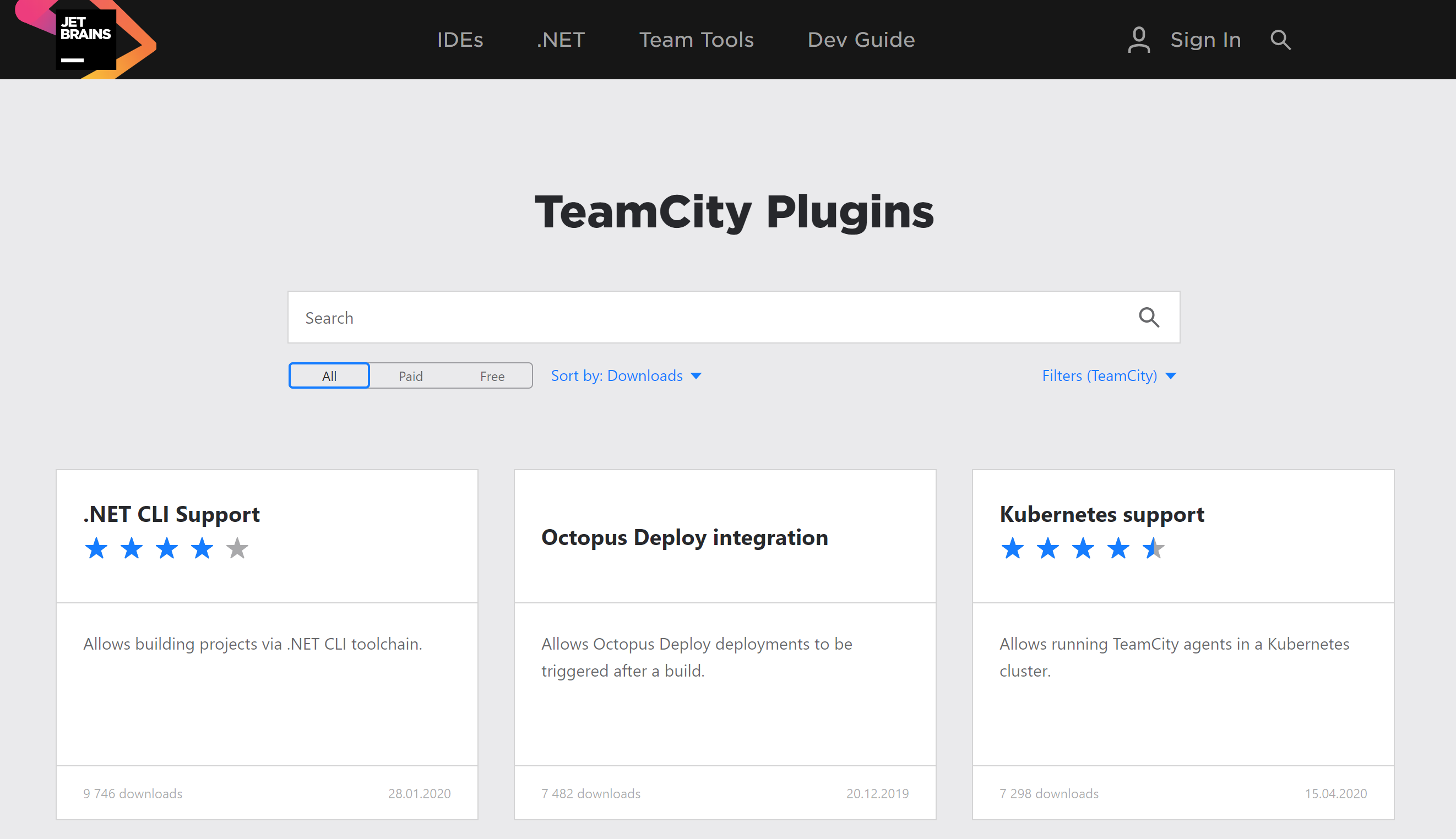
In 2020 it's more complex. Practically everything claims to "deploy" stuff automatically. Most cloud services, build servers and even bug trackers now have some basic deployment concepts. TeamCity, Azure DevOps and Atlassian Bamboo, for example, have concepts for releases and deployments, but they're generally a hook to call your bash script - not as powerful as Octopus. At the time of writing, despite little marketing, Octopus is the #2 plugin for the TeamCity marketplace, and one of the top plugins for Azure DevOps. This means we must be adding something that those tools lack natively.
Microsoft has Azure DevOps, although the momentum seems to be going towards GitHub Actions, and Amazon has CodeDeploy. Those services seem to act as loss-leaders for their cloud products. These all have functionality for simpler deployments, but in my opinion, I think their goal will be to stop at "good enough" - I can't see them investing in solving the more complex deployment scenarios. Azure DevOps probably came the closest in terms of deployment power to Octopus, but the momentum has stalled as the key employees move to GitHub Actions.
Then there are companies like Xebia and Harness, or CA and IBM's deployment tooling, which are sold "top-down." Just to find out the pricing, you need to talk to somebody, who will probably qualify you to figure out if you're a serious buyer or not. I believe that this sales model tends to corrupt - it makes product teams focus on building a product that demos well to the "buyer" (your boss's boss's boss). They end up focusing on features like "Twitter sentiment analysis as a blocker for deployments" or reporting dashboards, rather than genuinely useful features. It's the old, uninspiring Enterprise sales model.
In all this, I think we occupy an appealing middle-ground:
- We support the most complicated deployment scenarios, and we've innovated more in this space than anyone else.
- Rather than going "end-to-end" on CI/CD (adding source control, bug tracking, build, etc.), we've focused on going deep on deployments and operations/runbook automation, a space most of the end-to-end CI/CD tools haven't yet explored.
- We're going for the "best tool for the job (deployment and ops automation)" rather than "tries to do everything, none of it particularly well."
- We have no commissioned sales team, so we rely on bottom-up adoption, and our pricing is on our website.
- We're independent and not tied to any particular cloud or ecosystem.
- We're not VC-funded, and we're profitable and conservatively managed.
If I had to summarize our philosophy:
- We think that deployments are a complicated enough space that we can innovate for years to come. If you wanted to make a bug tracker or CI server, for example, there's not much new to invent. We think deployment is a whole new problem domain that needs dedicated tooling, not a tickbox feature. This is why we're so R&D focused.
- Unlike the "big enterprise sales" competition, we think deployment automation is a "Fortune 50,000" problem. And even if you are a Fortune 100, we still think the best solution for you is something that is adopted one team at a time, bottom-up, with consensus.
- Our software solves a valuable problem that lots of people have. By seeking to solve it well for the majority of the market, from small to very large organisations, we do a better job than people just focussing on the largest companies only. When large enterprises buy from us, they buy from a company with the deepest pool of customers with their problem. We invest heavily in making large companies succeed but our foundations are the hundreds of thousands of users we have from every size of company.
I think the world needs a cloud-agnostic, powerful deployment tool that's constantly innovating, and one that's designed to be adopted by teams bottom-up rather than sold top-down. And for as long as enough people agree, we'll be in business 😄
Our growth over time
So far I think our strategy is working, and our customers agree. We're not perfect, and there's always ways to improve, but generally we still get as much positive feedback from customers as we ever did. This is the best measurement of success.
If Octopus was VC-funded, I could point to announcements about our latest funding rounds as some kind of validation. Instead, we're a bootstrapped, conservatively managed, long-term oriented company. We've been profitable since day 1 and never had made a loss in any single month. There's no "exit plan" here; I love doing what we do, and would love to do it for decades to come.
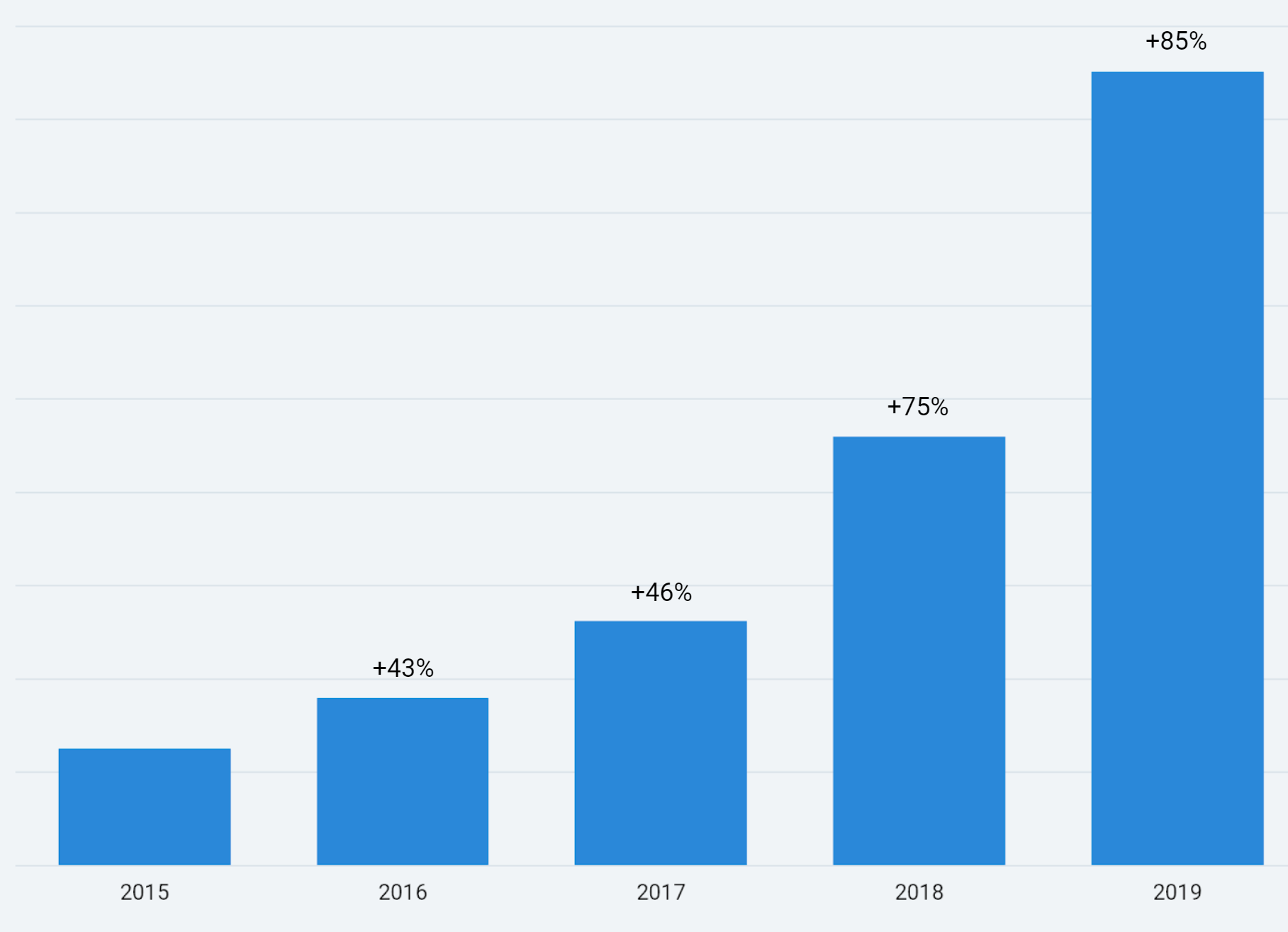
Revenue isn't a great measure, but if you assume Octopus is still in business because our customers agree we must be doing something well, then looking at revenue is the vote of confidence that we must be doing something useful.
What's next
We're still innovating. Here's our roadmap for what we're working on right now:
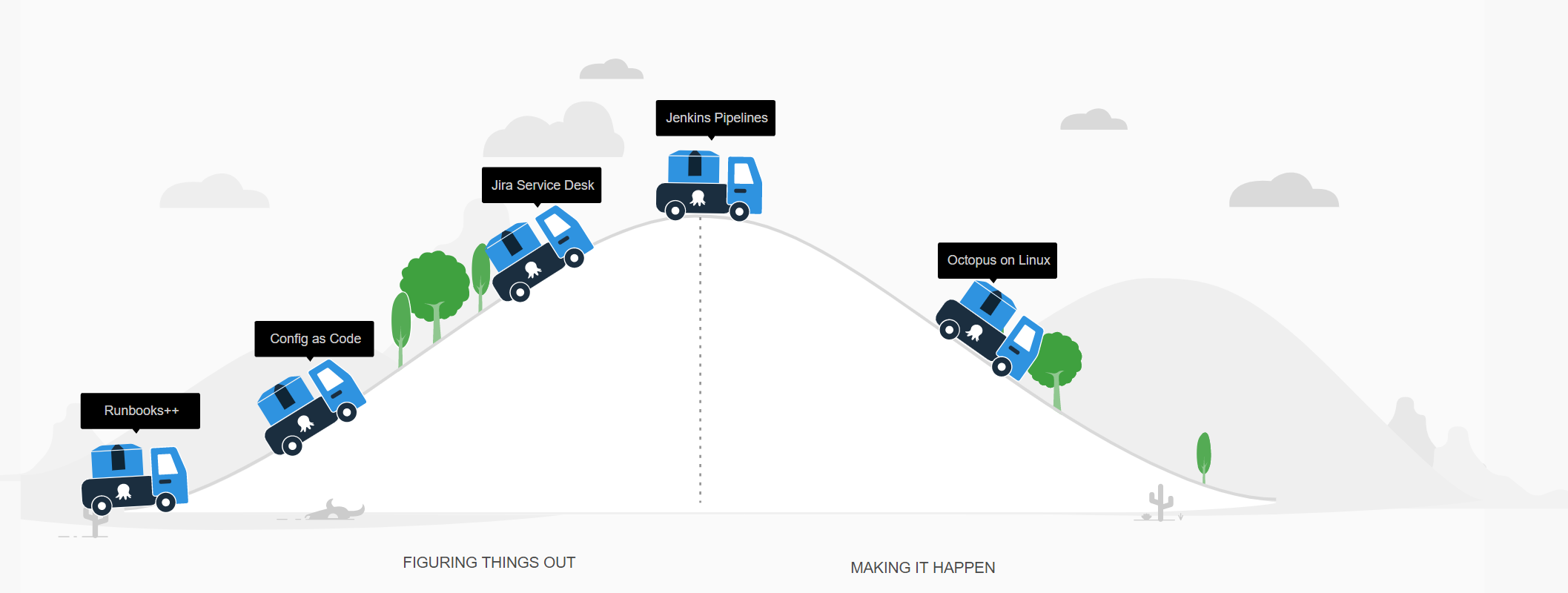
Here are two examples:
First, right now we're adding Configuration as Code support to Octopus. We're late to the party on this - customers have been asking us for this for a while. But, we're doing it very differently.
With other tools, when you start using configuration as code, you lose all UI support - or the UI becomes read-only at best. Azure DevOps with YAML reminds me of when we used CruiseControl.NET with Nant scripts in 2006 - I thought we evolved past that. Everyone asks for configuration as code, but when they find themselves hand-editing YAML, the sentiment seems to be a bit underwhelming.
With Octopus we're creating the best of both worlds. You can store your Octopus deployment configuration in Git, and even branch it, but the UI still works. We use HCL rather than YAML, and it's very human readable. But unlike the other tools, you can continue to edit both in the UI and in text.
Second, we recently launched Runbooks support. I think that this makes Octopus categorically different. (I’ll be writing about this in more detail in a following post.) Octopus is a platform that can automate not just the deployment, but all the other automation tasks you run - from disaster recovery to certificate renewals. We only launched it December last year, and already over a thousand customers use Octopus as an operations tool, not just a deployment tool. At the time of writing, Octopus is probably the world’s fastest growing runbook automation tool. It’s going to be exciting to see where this takes us.
Software release management, deployment, and operations automation is a vast space, with so much uncharted territory and ideas waiting to be discovered. We're having a lot of fun exploring this space and leading the way.
I hope you found this interesting. If there's something you'd like me to write more about, let me know in the comments. Thanks for reading!