Integration: ETL

As I outlined previously, we need to enable these two applications to share customer data:

A few people suggested having both applications share the same database, but that has some pitfalls. In coupling both applications to the same database, the ripple effect of change will become hard to manage over time.
A second solution, as suggested by Robert and Peter in the comments, is for each application to "own" an independent database, and to use an extract, transform and load process to push customer information from the Web Store into the Marketing application. Architecturally, it would look like this:
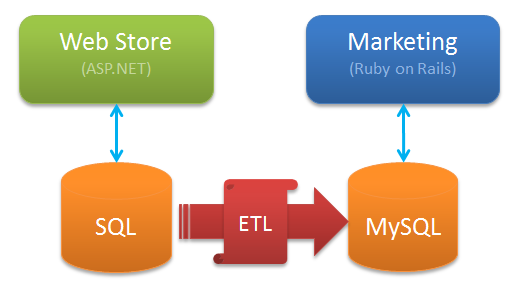
This approach means that:
- Each application can design and control its own database schema
- The storage and indexing of each database can be optimized for the access patterns of its application
- Changes can be made to either schema without having to co-ordinate the changes with the other team
Of course, point 3 is always murky - the Web Store team can't decide to drop the EmailAddress column without it having an effect on the Marketing team. But the Web Store team could de-normalize the tables to gain a performance increase without affecting the Marketing team.
Someone will need to own the ETL process, and changes in either schema will need to be co-ordinated with that person as part of the release plan. But overall changing an SSIS package or batch file is probably easier than changing database schemas. We can never eliminate the need for communication, but by decoupling the two applications, we gain many benefits.
Spaghetti ETL
An ETL approach works well when we're just talking about two applications, with one application needing a read only view of the other. But it gets messy when:
- We introduce more than one application
- Data changes need to flow bi-directionally
If you consider an environment with multiple applications needing data from each other, you could end up with something like this:
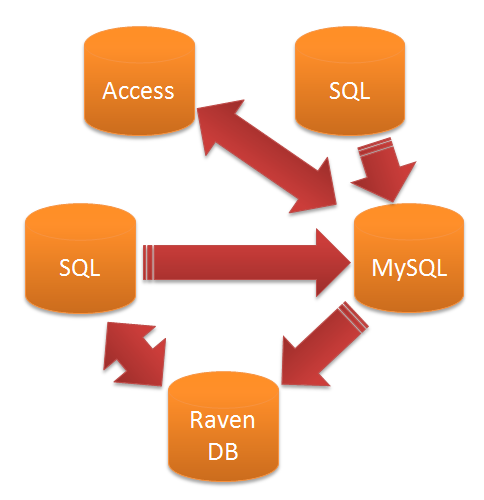
The cost of change in an environment like this can still be expensive, although it's probably easier than if they all used a single database. If a new application is added, it might need to source data from three, four or five other databases, which requires that many new ETL packages. The difficulty of scaling a system like this is the same as the difficulties described in the Mythical Man Month about scaling teams.
Staging databases and other ETL patterns can help here, but I'd personally try and avoid creating an environment like this. There's also one other problem with using ETL:
You lose context
As with shared databases, ETL scripts work on data. Unless the database uses some form of event sourcing, Working at the data level means we lose a lot of context. We can see the data, and we can even tell that it changed, but it's hard to tell why it changed. Figuring it out is like putting together the sequence of events that took place at a crime scene, based on the current state.

When the address changed, was it because the customer mis-typed their address the first time, or because they moved home? The application may have known that at the time the data was updated, but that probably wasn't persisted anywhere.
As with a crime scene, we can only glean so much from the data by examining its current state. Next up we'll look at ways to provide more context around why data changed.