Hybrid storage: Git+SQLite vs. RavenDB?

In Octopus, we use RavenDB as our database for almost everything. Over time, I'm noticing that we really keep two distinct sets of data in Raven, and I'm beginning to reconsider whether having one store for both of them is the best solution.
The two sets of data I'm referring to are:
- Definitions. Environments, machines, projects, deployment steps, variables, and so on. They define what will happen when you deploy something. There usually aren't more than a couple of thousand of any of them. As a user, you spend time crafting and modifying these.
- Records. These collections include releases, deployments, audit events, and so on. Basically, they are a record of the actions you've done using the definitions above. These collections can balloon out to many thousands, perhaps millions of documents. As a user, these are created from simple clicks or even automatically via API's/integration.
When diving in deeper, there are some other notable characteristics:
- Simple vs. complex: The first set tend to be very complicated documents, with a lot of nesting, dictionary properties, and so on - perfect for a document database. The second set tend to be small and flat, with just a handful of fields
- History: when you change variables or deployment steps, we take snapshots of them, so that old releases can still use the old values while new releases get the new values. This means that we keep multiple versions of the same document in Raven.
- Retention: retention policies only really apply to the second set of collections.
The first set of documents lend themselves well to a document database, but there are so few of them that I'm not sure we do need a database behind them. The second set of documents would probably work just as well (if not better) in a relational database.
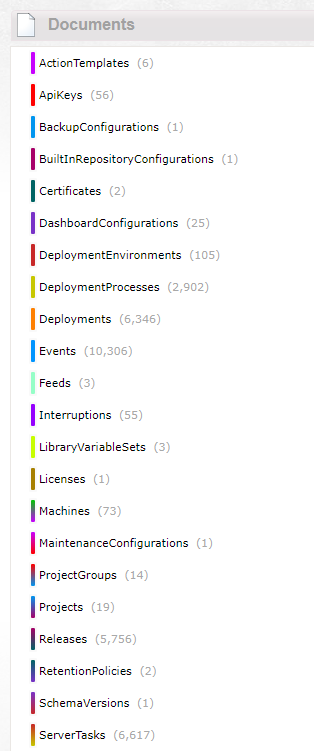
Right now, Raven makes a good store because it is both a document database (great for our complex definition documents) and is also able to handle our record data. But it's starting to strain. A customer with 43,000 documents sent us a backup, and it took 20+ minutes to rebuild all the indexes before it was usable. Audit events work nice until we have hundreds and thousands of them; ideally we'd keep them all and not apply a retention policy, but then we have to pay to index them all the time.
Perhaps, just maybe, a hybrid storage solution might make more sense?
Tonight I spent some time prototyping a Git-based "document" store. From a C# API point of view, the goal is for it to feel just as friendly as a document database:
using (var session = store.OpenSession())
{
session.Store(new Project("My project") { ... });
session.Store(new Project("Another project") { ... });
session.Commit("Added some projects");
}
Under the hood, it uses JSON.NET to serialize objects to JSON, and persists them on disk, followed by committing them to a local Git repository (libgit2sharp is amazing, by the way). What's exciting is that this would give our users a whole lot of benefits that come for free when using Git: viewing history, diffs, branching, merging, pushing to TFS or GitHub, and so on.
The missing feature is obviously indexing. Since these tend to be small data sets, however, I think we can probably get away with just putting everything in memory and filtering with LINQ when we need to. We could easily load a few thousand machines into a list, and keep them there until they are invalidated.
While this would work for the first set of documents I talked about, it wouldn't work for the second set. For that, I suspect we would switch to a relational database that can be embedded (probably SQLite). These records have few columns, are quite flat, and would only need to be indexed on one or two columns.
TeamCity appears to use a similar hybrid storage model, with project definitions and build configurations stored as XML files on disk, but records of individual builds stored in a database. As for Octopus, I don't know if or when we'll make the move, but it feels like a hybrid storage model that embraces the differences between the two sets of data is only going to become more compelling in the future.
In the mean time, if anyone is interested in collaborating on a Git-backed persistance solution, let me know :-)